Learn-as-you-go – Enabling mass adoption of condition prediction

Key Takeaways
- Three substantial barriers to successful adoption of predictive operations are: high quality historical sensor data, high quality ground truth data, and extensive operations expert participation
- A continuous learning approach that leverages operations expertise produces desired business results by highlighting and dispositioning interesting events in daily data.
In the years that we have been working with customers to remove operational inefficiencies by applying operational AI, we have seen several recurring challenges from the use of conventional data science methods and realized that a different approach is needed.
Quality sensor data history is limited.
Data retention policies vary widely but we see two common challenges.
- In some cases, very little data is stored. When there are only a few hours of data available, the value of using that data is low.
- In other cases, data is stored for much longer periods of time. However, that data is usually compressed in ways which remove important information. We have found that using multivariate, time series patterns provide better insights than traditional approaches relying on descriptive statistics or regression methods (more here). When data is compressed, the ability to benefit from those patterns is lost.
High quality ground truth data is hard to get.
Digital commerce and marketing platforms are designed to collect the kind of examples that support machine learning and fast decision making. They connect clicks with the possible factors that triggered them. Industrial operations usually lack the systems required to record ground truth (e.g. equipment failures and maintenance events) at this level of completeness.
Plants frequently lack a consistent data entry process and nomenclature. The same events may be called different things depending on who is entering the event and when it is being entered.
E.g. “Seal failure,” “door closure failure” or simply “maintenance” may all describe the same event.
A single failure may also be split into multiple entries making it very difficult to understand which events are distinct failure modes and which are actually a single failure.
E.g. An out of spec process result may be seen and first recorded as an out of cycle maintenance event because the tech on shift normally resolves all out of spec conditions this way. When early maintenance proves to be the wrong corrective action the same event shows up as a recalibration. When calibration does not resolve the problem, the same event shows up a 3rd time as a part replacement.
Operations expert participation is limited.
Operations experts are very busy keeping operations running. It is difficult to free up enough time in their schedules to provide diagnostic feedback or interpretations of problems which are not directly related to the fires they are putting out today. Because traditional analytics projects typically look at historical datasets, they are necessarily looking at problems that occurred in the past. When forced to choose between working on the problem of the day or working on a problem that was solved 7 months ago, the choice is generally, and unfortunately, easy to make.
Using a continuous approach to learning
We believe that a learn-as-you-go approach addresses these shortcomings. Figure 1 below illustrates the concept.
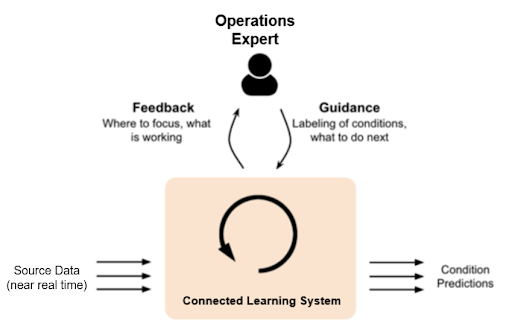
Fig 1 – Human guidance is used by the learning system to improve its observations and provide better predictions.
Some key points about this approach:
- Source data is taken directly from the equipment not from historical archives. Data is fed directly from the equipment via a protocol like OPC UA or MQTT or can be taken in near real time from a data historian. This approach addresses gaps in data storage duration and compression methods. It also ensures that analysis is performed “in the now” – That is, it provides feedback about operations currently underway.
- Feedback is generated from the learn-as-you-go system based on patterns. The learning system takes data and automatically determines which patterns make up normal behavior. Based on these observations, distinct unusual patterns are flagged for the operations expert to review. These alerts are provided along with explanatory displays of real-time data to make it easy for the operations expert to interpret the causes and implement a solution.

Fig 2 – An asset dashboard displays the status of various equipment or processes being monitored. Grey means no attention is needed. An orange alert means that a previously unseen condition has been detected. A red alert means a previously identified undesirable condition has been detected.
By using patterns to identify only interesting behaviors, the amount of time users must spend reviewing data is minimized. This approach avoids the limitations of mining historical data for a well documented set of interesting events. The approach also automatically adapts to changing plant conditions as it sees new patterns emerge.
- Guidance is provided by reviewing patterns of behavior. The operations expert looks at the patterns and correlated signals for each alert generated by the learning system. This process may involve comparing these patterns to other patterns in time or across equipment to understand the differences.

Fig 3a – Raw time series data associated with the alert is displayed. In this case data shows a drop in the compressor suction temperature signal, a relatively sharp rise in the N2 filter DP signal and slow, gradual rise in the NDE primary seal leakage flow signal.
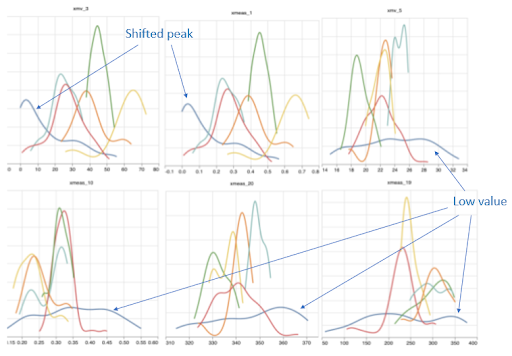
Fig 3b – Distribution of signal values per sensor (each a different chart) for a range of different conditions (each a different color line). In the example above, the dark blue condition shows a low value compared to other conditions in 4 of 6 sensors and a significantly shifted peak in 2 of 6 sensors.
By comparing underlying behaviors between different time periods and signals, the operations expert can better understand the root cause and importance of each alert. This knowledge can be used not only to label the event but to take corrective action.
At this point, the operations expert will classify the event as a new condition by providing it a name. Alternatively, they may classify it as an existing condition by selecting from among the names they have already provided in earlier feedback reviews. If the event is interesting and they would like to be alerted when this type of event occurs again, they can set the system to generate notifications. Otherwise, events of this type will not be reported in the dashboard.
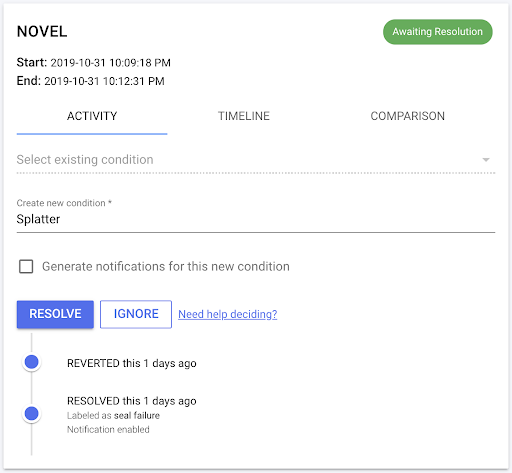
Fig 4 – The software provides a simple dialog box which allows the operations expert to label each event as it is detected or defer labeling until more information becomes available.
This process of review and guidance provides the operations expert insight to the issues they are seeing today. They are able to more effectively address those issues using the feedback while simultaneously improving the learning system’s performance.
- The learning system updates itself with operations expert feedback to improve performance. The learning system’s algorithms use the guidance to label data and update the underlying model to correctly classify new data. Updates happen automatically. They do not require special training or interaction by the operations expert. This makes widespread adoption of ML feasible using teams you already have.
- Conditions are output for consumption by the plant’s normal workflow systems. In parallel with providing feedback via a dashboard, the learning system can also output its findings to the plant’s Enterprise Asset Management (EAM) system. From here the plant can follow its normal business processes to make better decisions. Simple, programmatic integration of data and alerts with existing systems makes widespread deployment of ML feasible using the systems you already have.
We believe that the learn-as-you-go approach makes widespread adoption of predictive production operations feasible because it addresses key shortcomings in deploying such systems today.
- Historical data which is difficult to obtain and hard to interpret is not required to start.
- Current operational data is used directly, minimizing the effect of sensor data compression strategies.
- The focus on current data makes engagement with the operations expert easier because it aligns their data analysis priorities with their day-to-day operational priorities.